解释器模式,这个模式我觉得是这些模式中最不好理解的模式,解释器模式是用来干啥的呢?比如说我们有一段英文或者一段公式,我们需要知道其中表达的意思到底是啥?(假如我们起初并不理解)也就是说,我们需要一个”解释人”,该角色就是我们的联络官或者叫做解释器,用来翻译我们的文本或者公式,翻译成我们能理解的最小的基础单元,听着是不是还云里雾里地?大家都知道编译器吧,一般的编译器分为词法分析器、语法分析器、语义分析器、中间代码优化器以及最终的代码生成器等,而我的理解,解释器就类似于其中的语法分析器的作用,专门负责语法文本的解析作用。
定义
解释器模式(Interpreter Pattern)提供了评估语言的语法或者表达式的方式,属于一种行为型的设计模式。
解释器模式的英文原话是:
Given a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language.
意思是:给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
简单来说,就是我们可以定义一种语法比如就是一个表达式如:a-b+c,起初我们并不知道这个句子想要携带信息或者执行什么操作,然后我们要定义一个解析器来进行表达式解析,以便得到正确的结果。
对于表达式:a-b+c 这种,我们做个简单的分析,a、b、c 这种我们又叫做运算参数,+、- 符号这种我们称之为运算符号,也就说这类表达式我们可以将其抽象为两种角色:运算参数、运算符号。运算参数一般就是英文字母,执行时各个参数需要赋上具体的数字值去替代英文字母执行,运算参数有一个共同点就是不管是 a、b 或者其它参数,除了被赋值之外不需要做其它任何处理,是执行时的最小单元,在解释器模式中被称为终结符号。运算符号是进行运算时具体要被解释器解释执行的部分,想象一下,加入我们计算机不知道如何处理类似 +、- 这种符号,我们是不要针对每一个符号写一个解释方法,以便告诉计算机该符号需要进行何种操作,这也就是解释器模式的核心——需要完成逻辑的解释执行操作,而运算符号在解释器模式中也被称为非终结符号。
组成角色
解释器模式的通用类图设计如下: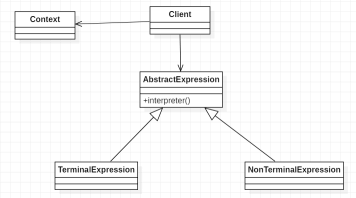
通常包含如下角色:
- 抽象解释器(AbstractExpression):抽象解释器是一个上层抽象类,用来抽取定义公共的解释方法:interpreter,具体的解释任务交给子类去完成;
- 终结符表达式(TerminalExpression):是抽象解释器的子类,实现了与文法中的元素相关的解释操作。一般模式中只会有一个终结符表达式也就是终结符的类,但是会有多个实例,比如:a、b、c,这些终结符号可以任意多种但是只有一个类来描述;
- 非终结符表达式(NonTerminalExpression):也是抽象解释器的子类,用来实现文法中与终结符相关的操作。该角色一般会有多个实现类,比如 +、- 运算符号就各自对应一种类实现,分别对应加法解释类和减法解释类,非终结符表达式的类的个数一般会有很多,因为我们可执行的操作一般会有很多,这也从侧面加剧了该模式下类设计的复杂性;
- 上下文(Context):上下文一般用来定义各个解释器需要的数据或公共功能,比如上面的表达式,我们使用上下文来保存各个参数的值,一般是一个 HashMap 对象,以便后面所有解释器都可以使用该上下文来获取参数值;
优缺点
解释器模式的优点:
- 拓展性强:修改文法规则只需要修改相应的非终结符表达式就可以了,即增加非终结符类就可以了。
解释器模式的缺点: - 采用递归调用方法,不利于调试,增加了系统的复杂性以及降低了系统执行的效率;
- 解释器模式比较容易造成类设计的膨胀,主要是非终结符表达式类会随着系统的复杂性而膨胀;
- 可利用的场景比较少;
- 对于比较复杂的文法不好解析。
应用场景
- 一个简单语法需要解释的场景,如:sql语法分析,用来解析那种比较标准的字符集;
- 重复发生的问题可以使用解释器模式,如:日志分析,日志分析时基础数据是相同的类似于我们的终结符,但是日志格式往往是各异的,类似于非终结符,只需要指定具体的实现类即可。
使用实例
现在我们以一个最简单的例子:a+b,我们要做的就是解释执行这段语法文本,a 和 b是两个字母也叫做两个变量,我们需要使用一个 “+” 符号来将这俩变量连接起来,假设我们的语言并不知道符号 “+”是什么作用,具体作用需要我们去实现(假设我们并不知道 + 其实是加法的意思),示例比较简单,只是为了说明解释器模式没别的意思。
首先是我们的上下文类,该类负责模式中一些上下文数据的存储,这里我们使用 context 存储运算符号 +,实现代码如下:
// 上下文类,这里只是简单说明下,实际的context可没这么简单
class Context {
private String symbol = "";
public Context(String symbol) {
this.symbol = symbol;
}
public String getSymbol() {
return symbol;
}
}然后是我们的抽象解释器角色:
// 抽象解释器
abstract class AbstractExpression {
// 解释器接口
abstract int interpreter(Context context);
}然后是我们的终结符和非终结符类:
// 终结符,即我们的参数构造类
class TerminalExpression extends AbstractExpression{
private Integer arg;
public TerminalExpression(Integer arg) {
this.arg = arg;
}
@Override
int interpreter(Context context) {
return this.arg;
}
}
// 非终结符,即我们的运算符构造类
class NonTerminalExpression extends AbstractExpression {
// 代表运算符两侧的参数,即a、b
private AbstractExpression left;
private AbstractExpression right;
public NonTerminalExpression(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
int interpreter(Context context) {
// 实现具体的 a +b 的解释执行操作
if (!context.getSymbol().equalsIgnoreCase("")) {
return this.left.interpreter(context) + this.right.interpreter(context);
}
return 0;
}
}最后是测试类:
AbstractExpression left = new TerminalExpression(12);
AbstractExpression right = new TerminalExpression(34);
AbstractExpression calExpression = new NonTerminalExpression(left, right);
Context context = new Context("+");
Integer result = calExpression.interpreter(context);
System.out.println(result); // 46总结
这节我们主要介绍了解释器模式的定义以及使用示例,解释器模式实际使用的场景并不多,但是又是一种比较复杂的设计模式,需要引起我们的重视,最后大家可以思考下,上面只是实现了最简单的 a + b,如果要实现 a + b - c 这种文法解析,又该如何实现呢,欢迎大家积极思考。

