java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核心的一个类,因此如果要透彻地了解Java中的线程池,必须先了解这个类。
线程池使用场景:并行操作,异步提交等
简单理解,它就是一个管理线程的池子。具体作用:
- 它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。
- 提高响应速度。 如果任务到达了,相对于从线程池拿线程,重新去创建一条线程执行,速度肯定慢很多。
- 重复利用。 线程用完,再放回池子,可以达到重复利用的效果,节省资源。
构造方法
构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)几个核心参数的作用:
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:空闲超时时间
- unit:时间单位
- workQueue:工作队列
- threadFactory:线程工厂
- handler:拒绝策略
假设:corePoolSize=5,maximumPoolSize=10,workQueue=10。如果有30个任务提交,线程池的执行机制是什么样的?
- 先使用corePoolSize运行5个任务,接下来会装10个到workQueue中。后面15个的话,会先判断maximumPoolSize,如果大于corePoolSize,会再次创建maximumPoolSize-corePoolSize 个线程执行。目前已经有20个任务在执行了,剩下来的10个会被根据拒绝策略被拒绝掉。
四种拒绝策略
- DiscardOldestPolicy:丢弃最老的任务
- DiscardPolicy:直接丢弃
- AbortPolicy:抛出异常
- CallerRunsPolicy:等待后续的线程执行
可以实现RejectedExecutionHandler接口,自定义拒绝策略
五种状态
private static final int COUNT_BITS = Integer.SIZE - 3;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS; // 111
private static final int SHUTDOWN = 0 << COUNT_BITS; // 000
private static final int STOP = 1 << COUNT_BITS; // 001
private static final int TIDYING = 2 << COUNT_BITS; // 010
private static final int TERMINATED = 3 << COUNT_BITS; // 011- RUNNING(111):运行状态,可以接受新任务,也可以处理队列中任务
- SHUTDOWN(000):待关闭状态,不再接受新任务,但是可以继续处理队列中的任务
- STOP(001):停止状态,不接收新任务,并且会尝试结束执行中任务,当线工作线程数为0时,进入TIDYING状态
- TIDYING(010):整理状态,此时任务都执行完毕,并且也没有工作线程,执行terminated方法后进入TERMINATED状态
- TERMINATED(011):终止状态,此时线程池完全终止了,并且成功释放了所有资源
五种状态的扭转图如下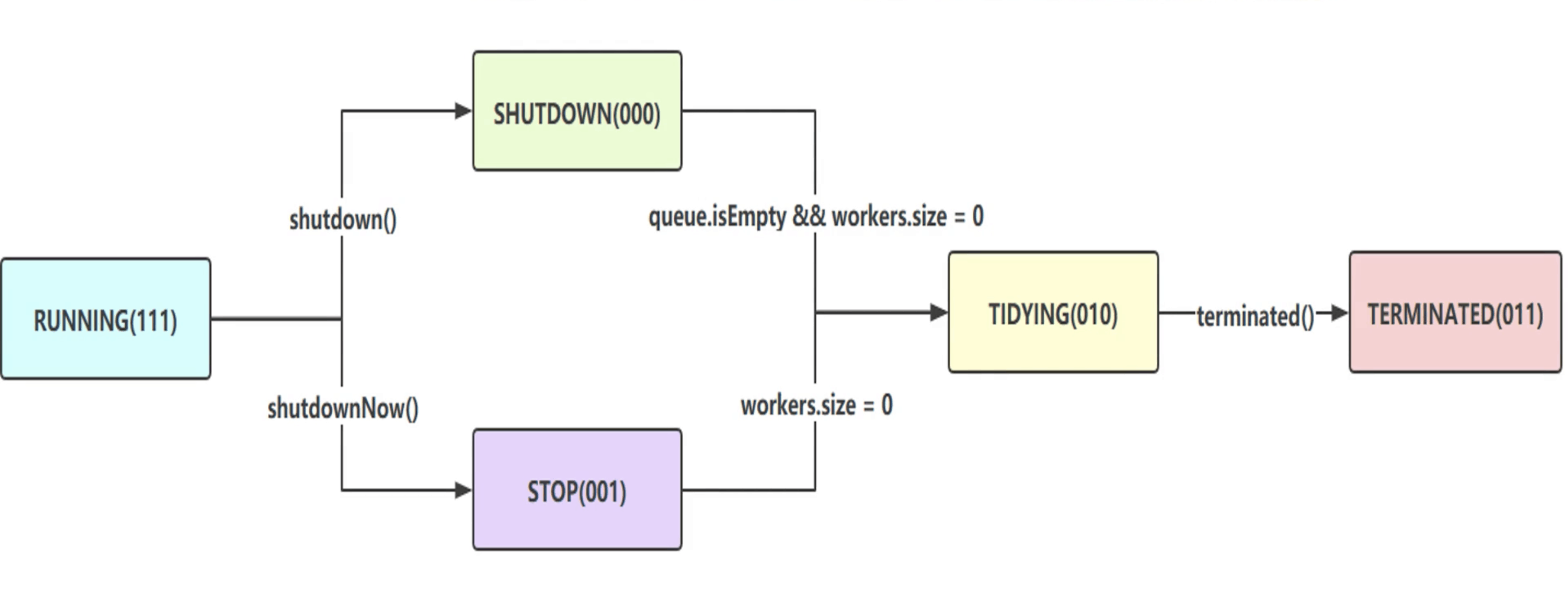
获取线程状态和工作线程数量分析
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));ctl 这个变量用于保存当前容器的运行状态和容器大小,并存在于ThreadPoolExecutor的整个生命周期 (32bit = 3 + 29),高三位去表示状态,低29位表示工作线程数量
private static final int COUNT_BITS = Integer.SIZE - 3; // Integer.SIZE = 32
private static final int CAPACITY = (1 << COUNT_BITS) - 1;COUNT_BITS就是低29位,CAPACITY相当于掩码_
private static int runStateOf(int c) { return c & ~CAPACITY; } // ~CAPACITY表示取反,获得高三位,得到运行状态
private static int workerCountOf(int c) { return c & CAPACITY; } // 得到低29位,worker的运行数量线程池的工作队列
线程池都有哪几种工作队列?
- ArrayBlockingQueue
- LinkedBlockingQueue
- DelayQueue
- PriorityBlockingQueue
- SynchronousQueue
ArrayBlockingQueue
ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。
LinkedBlockingQueue
LinkedBlockingQueue(可设置容量队列)基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列。
DelayQueue
DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue
PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列。
SynchronousQueue
ynchronousQueue(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
线程池参数配置
线程池参数配置一般有两种类型:CPU密集型和IO密集型
- CPU密集型:corePoolSize = CPU核心数 + 1 或者 CPU核心数 x 2, maximumPoolSize =cpu数量 x 2 + 1。目的减少线程的切换
- IO密集型:corePoolSize = CPU核心数 / (1 - 阻塞系数),maximumPoolSize = (cpu数量 / (1 - 阻塞系数)) x 2。阻塞系数在
0.8~0.9之间。目的减少线程的等待时间
以上只是大致的配置,具体情况根据业务情况自行判断使用JDK的ThreadPoolExecutor配置
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.ThreadFactory; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; /** * @author fangxi */ @Configuration public class ThreadPoolConfiguration { @Bean public ThreadPoolExecutor threadPoolExecutor() { final int cpu = Runtime.getRuntime().availableProcessors(); final int corePoolSize = cpu + 1; final int maximumPoolSize = cpu * 2 + 1; final long keepAliveTime = 1L; final TimeUnit timeUnit = TimeUnit.SECONDS; final int maxQueueNum = 1 << 7; return new ThreadPoolExecutor( corePoolSize, maximumPoolSize, keepAliveTime, timeUnit, new LinkedBlockingQueue<>(maxQueueNum), new CustomThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy() ); } private static class CustomThreadFactory implements ThreadFactory { private final ThreadGroup group; private final AtomicInteger threadNumber = new AtomicInteger(1); private final String namePrefix; CustomThreadFactory() { SecurityManager s = System.getSecurityManager(); group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); AtomicInteger poolNumber = new AtomicInteger(1); namePrefix = "fx-pool-" + poolNumber.getAndIncrement() + "-thread-"; } @Override public Thread newThread(Runnable runnable) { Thread thread = new Thread(group, runnable, namePrefix + threadNumber.getAndIncrement(), 0); // 设置不是守护线程 if (thread.isDaemon()) { thread.setDaemon(false); } // 设置优先级为默认的 if (thread.getPriority() != Thread.NORM_PRIORITY) { thread.setPriority(Thread.NORM_PRIORITY); } return thread; } } }
使用SpringBoot配置
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
public class ThreadPoolConfiguration {
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
final int cpu = Runtime.getRuntime().availableProcessors();
final int corePoolSize = cpu + 1;
final int maximumPoolSize = cpu * 2 + 1;
final int keepAliveTime = 1;
final int maxQueueNum = 1 << 7;
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maximumPoolSize);
executor.setQueueCapacity(maxQueueNum);
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setKeepAliveSeconds(keepAliveTime);
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix("fxipp-pool-thread-");
executor.initialize();
return executor;
}
}核心方法解析
整体工作流程分析
先看一下线程池的任务流程图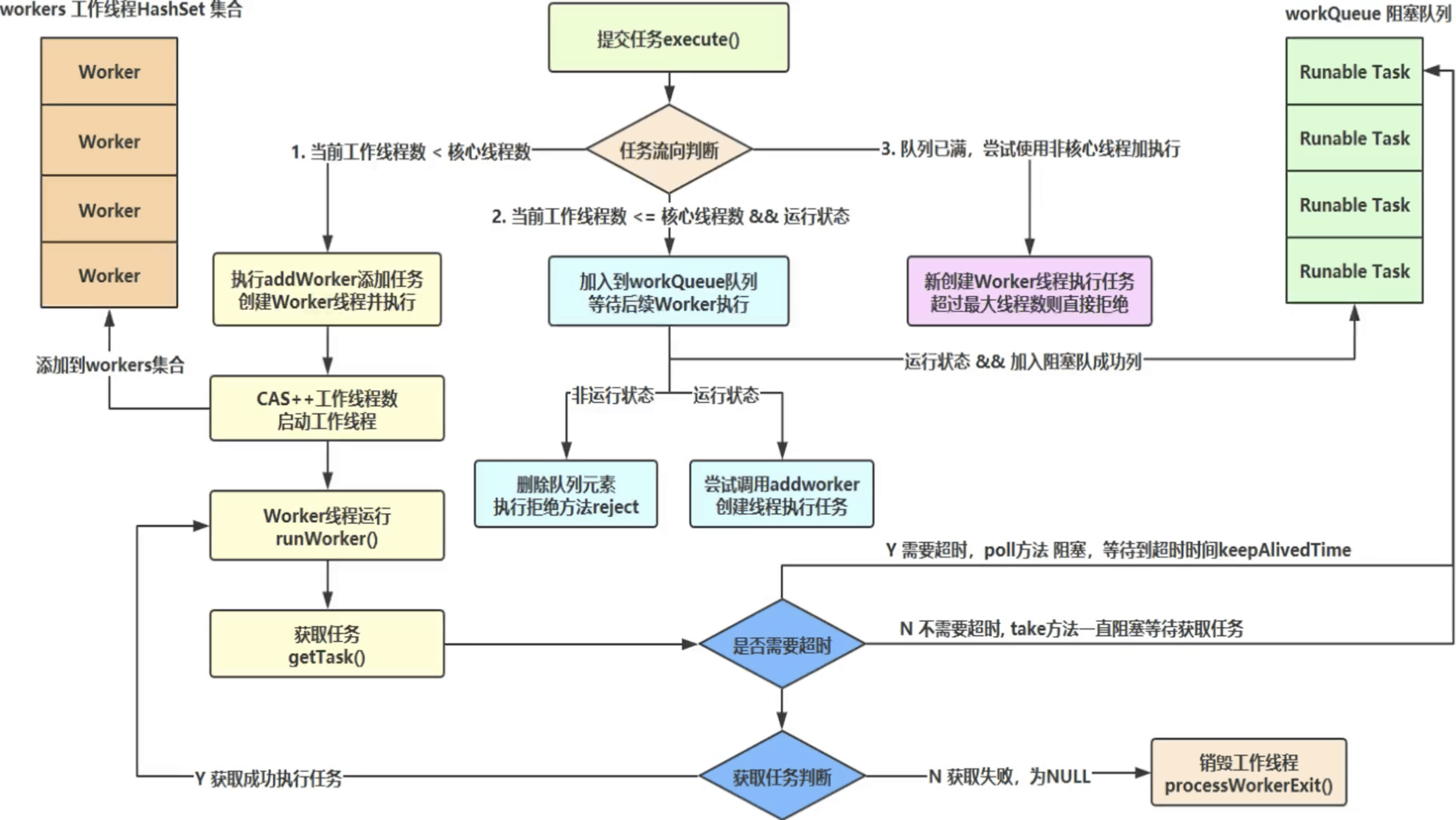
- execute(): 起始方法
- Worker: 执行任务的角色, 存储在workers中。worker的目的就是为了执行一个个的任务。一个worker对象就是一个线程
- Runnable Task: 阻塞队列,如果核心线程数满了,任务会放在该队列
execute() 方法分析
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 如果当前线程池中的线程数少于corePoolSize,则调用addWorker(任务, 是否核心线程)创建一个新核心线程执行任务
// workerCountOf: 获取当前核心线程数
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果核心线程已满,调用workQueue.offer() 方法,把当前任务添加到队列中。
// 如果当前是运行状态 && 成功添加到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
// 重新检查状态
int recheck = ctl.get();
// 如果不是运行状态,进行删除队列元素并执行拒绝策略
if (!isRunning(recheck) && remove(command))
reject(command);
// 工作线程数为0,而且是运行状态
else if (workerCountOf(recheck) == 0)
// 第一个参数是null,表示没有任务加入。第二个参数是false,说明当前线程池中工作线程数大于corePoolSize
// 还需要创建一个线程执行任务
addWorker(null, false);
}
// 加入失败,核心线程已满,队列已满,则尝试创建一个线程执行
else if (!addWorker(command, false))
// 创建线程失败,执行拒绝策略
reject(command);
}addWorker() 方法分析
对一些参数进行判断,如果通过则创建新线程执行任务
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
// 获取运行状态
int rs = runStateOf(c);
// 1.线程池已经shutdown之后,直接拒绝
// 2. showdown状态时,传进来的任务为空,且队列不为空,是允许添加新线程的。如果条件取反,就表示不允许添加worker
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// 获取worker工作线程数
int wc = workerCountOf(c);
// 如果工作线程数大于默认容量或者大于动态线程数大小,则直接返回false,表示不能添加worker
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 通过cas操作添加工作线程数量,如果成功,直接退出执行for循环之后的操作。失败则重试。数量+1,线程还没创建
if (compareAndIncrementWorkerCount(c))
break retry;
// 再次获取运行状态
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 上面代码主要对workers的数量做cas + 1操作,下面才是构建worker对象
boolean workerStarted = false; // worker是否已经启动
boolean workerAdded = false; // worker是否添加完成
Worker w = null;
try {
// 创建一个worker,入参是当前提交的任务.worker的目的就是开启新线程执行一个个的任务
w = new Worker(firstTask);
// 获取当前worker中的线程
final Thread t = w.thread;
if (t != null) {
// 获取worker的锁
final ReentrantLock mainLock = this.mainLock;
// 加锁阻塞,避免并发
mainLock.lock();
try {
// 获取运行状态
int rs = runStateOf(ctl.get());
// 如果是运行状态,或者SHUTDOWN状态且firstTask是空(队列中有任务),才能添加到workers集合中
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 任务封装到worker里面,还没start
if (t.isAlive())
throw new IllegalThreadStateException();
// 添加到工作集合
workers.add(w);
// 如果集合中的工作线程数大于最大线程数,这个最大线程数是曾经出现过的最大线程数
int s = workers.size();
if (s > largestPoolSize)
// 更新线程池中出现的最大线程数
largestPoolSize = s;
// 工作线程已经添加完毕,打个标识
workerAdded = true;
}
} finally {
// 释放锁
mainLock.unlock();
}
if (workerAdded) {
// 如果添加成功,则启动工作线程。并标记启动成功
t.start();
workerStarted = true;
}
}
} finally {
// 如果启动线程失败,则调用addWorkerFailed。递减实际工作线程数,还原之前的cas+1操作
if (!workerStarted)
addWorkerFailed(w);
}
// 返回是否启动成功标识
return workerStarted;
}runWorker() 方法分析
runWorker主要执行任务
- addWorker主要是添加工作线程
- runWorker具体的执行任务方法
- 如果task不为空,则直接执行
- 如果task为空,通过getTask()方法获取任务,如果取到的不为空则执行该任务
- 执行完毕后,通过while循环继续获取任务
- 如果还是获取不到任务,这个runWorker()执行完毕
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
// 标记变量,表示执行中是否出现异常
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
// 上锁不是为了并发控制,因为worker本身就是单线程执行的。
w.lock();
// 判断是否被中断
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 任务运行前缀处理器
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 任务运行后缀处理器
afterExecute(task, thrown);
}
} finally {
task = null;
// 记录该Worker完成数量
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 如果发生异常,删除该任务,销毁工作线程
processWorkerExit(w, completedAbruptly);
}
}
